Umělou inteligenci v ČEPS zavádíme na třech úrovních
Usilujeme o rovnováhu mezi komplexitou a datovou bezpečností, vysvětluje v rozhovoru Přemysl Voráč, který ve společnosti ČEPS vede oddělení EMS a AI. Jeho dynamicky rostoucí tým má kromě implementace velkých jazykových modelů na starost například také modely pro predikce ztrát a systémové odchylky za využití strojového učení či vývoj interních aplikací, které pomáhají zajistit bezpečnost provozu přenosové soustavy České republiky.

In an interview with Přemysl Voráč, Head of EMS & AI at ČEPS, we discuss how the Czech electricity TSO is rolling out large language models across its operations, applying machine learning to predict system imbalance and technical losses, and validating the results of the Core Capacity Calculation tool at the national level.
Ve společnosti ČEPS pracujete od roku 2015, kdy jste nastoupil do oddělení EMS. Od roku 2019 oddělení vedete, dnes už pod názvem EMS a AI. Jak se v průběhu deseti let proměnila vaše agenda?
Je to obrovská změna. V roce 2015 jsem nastupoval jako specialista a měl na starosti zavedení nového způsobu modelování elektrizačních sítí pomocí Common Grid Model Exchange Standardu. V té době to byla jedna z mála interně vyvíjených aplikací. Byli jsme převážně energetici, kteří kódovali. Přístup DevOps v té době nepřicházel v úvahu [termín DevOps vychází z anglických výrazů Development a IT Operations; označuje přístup k vývoji softwarových aplikací a služeb, který klade důraz na spolupráci mezi dříve izolovanými rolemi, jako jsou vývoj, provoz IT nebo kontrola kvality a zabezpečení, pozn. red.].
Naše role se začala proměňovat, když za námi přišli kolegové ze sekce Energetického trhu s prosbou o pomoc s některými procesy. Od té doby jsme začali těmto „interním zákazníkům“ nabízet vývojové služby. Nově jsme vyvíjeli aplikace nejen pro dispečery, ale i energetický obchod – například pro výpočet kapacit, tehdy ještě metodou Available Transfer Capacity (ATC). Byli jsme schopni manuální proces částečně zautomatizovat pomocí nové aplikace.
Díky tomu, že jsme se osvědčili, naše agenda narůstala. Dnes se tedy nadále věnujeme energetické doméně a podpoře dispečerského řídicího systému, ale přidala se k tomu například digitalizace přípravy provozu v delších časových horizontech.
Přípravy provozu jsou týdenní, měsíční, roční. Vyvinuli jste pro všechny tyto horizonty jednotnou interní aplikaci?
Nástroj, který je dnes nasazený, se začal rodit v roce 2019. Od roku 2021 jsme ho začali přetavovat v dospělejší aplikaci, která má backend, frontend a umí dělat týdenní, měsíční a roční přípravu. Nestačilo ale jen vytvořit model, aplikaci jsme museli doplnit také o analýzy bezpečnosti – např. load flow a kontingenční analýzu. A postupně ji funkčně rozšiřujeme.
Zmínil jste aplikaci pro výpočet kapacit metodou ATC. Pomáháte i s výpočtem kapacit novou metodou flow-based?
Flow-based výpočtu kapacit se věnujeme od roku 2018. Jsem aktivním členem pracovní skupiny pro IT (Core IT Working Group) v rámci Core Capacity Calculation Region (Core CCR), který postupně zavádí flow-based výpočty kapacit v různých časových horizontech. Nejprve byl spuštěn day-ahead, následoval intra-day a nyní se připravuje dlouhodobý výpočet.
V rámci těchto procesů s kolegy ze sekce Energetický trh řešíme proces interní validace – tedy zda naše síť bezpečně zvládne přenos vypočtených kapacit. Ověřujeme, že i kdyby nastaly provozně nebezpečné stavy, nedostaneme se za hranu přijatelnosti. K tomu využíváme poměrně pokročilý nástroj Security Constrained Optimal Power Flow, který dokáže určit, jakou sadu nápravných opatření je možné použít při problematických provozních stavech – např. přepojit rozvodnu či změnit odbočku trafa.
Day-ahead validace funguje tak, že do centrální platformy (Core Capacity Calculation tool, CCCt) pošleme s dvoudenním předstihem 24 individuálních modelů české přenosové soustavy. Tyto modely představují abstraktní reprezentaci konkrétního stavu přenosové soustavy České republiky v konkrétním čase, která obsahuje sadu uzlů, větví, transformátorů, generátorů, odběrů a tlumivek včetně jejich plánovaného nasazení a stavu topologie. Zpět dostaneme spojený model všech soustav zapojených v Core CCR, a to ve dvaceti čtyřech řezech – tedy hodinovém rozlišení.
Se spojeným modelem obdržíme také tzv. flow based doménu: množinu všech provozně bezpečných obchodních toků mezi bidding zónami. Jedna kombinace toků mezi bidding zónami představuje přesně jeden bod, který se může nacházet buď uvnitř, nebo vně tohoto n-rozměrného polyhedronu. Aby byla zajištěna bezpečnost systému, musí se nacházet uvnitř.
Proto se následně spojený model snažíme dostat pod provozní stres – hledáme potenciálně nebezpečné scénáře (např. výpadky některých prvků soustavy či zvýšené odběry ve vybraných místech), ve kterých by mohlo dojít k proudovému přetížení. Pokud takové riziko identifikujeme (model dostaneme blízko hranici flow based domény), navrhujeme možné úpravy kapacit vybraných bodů sítě. V podobném gardu probíhá také intra-day výpočet, akorát bez optimalizace. Máme na něj totiž místo několika hodin jen asi 40 minut. Zde by se nabízelo využití AI nástrojů – mluví pro ně rychlost, proti nim ale riziko nepřesností.
„Ověřujeme, že i kdyby nastaly provozně nebezpečné stavy, nedostaneme se za hranu přijatelnosti.

PREDIKCE SYSTÉMOVÉ ODCHYLKY A ZTRÁT
Vyvíjíte i aplikace, které se netýkají primárně zajišťování bezpečnosti provozu?
Příkladem úspěšného využití strojového učení jsou u nás predikce systémové odchylky a ztrát, kterým se věnujeme od roku 2020. Především predikce ztrát na vedeních přenosové soustavy umožnila efektivnější nákup elektrické energie potřebné k jejich pokrytí.
Jak taková predikce funguje?
Používáme algoritmy založené na struktuře tzv. gradientně boostovaných stromů, jako jsou CatBoost a XGBoost. Do nich vstupují data o počasí, ztrátách v minulosti, přeshraničním přenosu a tranzitu, spotřebě, výrobě obnovitelných zdrojů a dalších systémových proměnných. Zásadní je, že výsledky těchto algoritmů jsou tzv. vysvětlitelné – umožňují posoudit, jakou mají jednotlivé časové řady váhu, tedy jak ovlivňují výsledek. To nám umožňuje dlouhodobě zajišťovat přesnost a vysvětlitelnost predikce. Kolegové ze sekce Energetického trhu, kteří s výsledky pracují, se na ni pak mohou při optimalizaci svých nákupních strategií spolehnout.
V případě systémové odchylky je přístup podobný?
Algoritmy ano, vstupní faktory se liší. U každého modelu je stěžejní nejen jej správně nadefinovat a nakrmit kvalitními daty, ale také průběžně monitorovat jeho přesnost. Proto vždy sledujeme nějaké KPI (např. střední absolutní chybu nebo střední absolutní procentuální chybu), pro které máme nastavené mezní hodnoty, při jejichž překročení se modelu začnou věnovat kolegové machine learning inženýři. Díky tomuto systému včas identifikujeme potenciální problém a zajistíme nápravu.
NASAZENÍ VELKÝCH JAZYKOVÝCH MODELŮ
Kdy do vaší práce vstoupily velké jazykové modely a umělá inteligence?
Do umělé inteligence jsme se pustili v roce 2020 s pilotním projektem ARTIC, který ukázal, že její využití dává smysl. Po jeho skončení v roce 2022 jsme vypracovali a začali implementovat strategii pro vybudování skutečně funkčního interního AI týmu, schopného vyvíjet vlastní modely využívající strojové učení. O rok později jsme tuto strategii rozšířili o adopci velkých jazykových modelů (LLM). Dnes náš AI tým tvoří pět lidí a do popředí jeho agendy se dostává adopce LLM napříč naší firmou. Pro predikce časových řad, jako jsou ztráty nebo odchylka, zatím velké jazykové modely nevyužíváme.
Jak o integraci LLM uvažujete?
Usilujeme o rovnováhu mezi komplexitou a datovou bezpečností. Na jedné straně je žádoucí, aby firma mohla nástroje umělé inteligence využívat a měla k dispozici nejlepší řešení, která trh nabízí. Na druhé straně je ale riziko toho, že jakákoli data poslaná do ChatGPT zůstanou v OpenAI.
Nakonec jsme se rozhodli implementovat produkty na třech úrovních (viz Obrázek č. 1). V případech, kdy jde o zpracování veřejných dat a řešení není příliš komplexní, mohou naši zaměstnanci využívat ChatGPT. K dispozici mají byznysovou licenci, při jejímž využití se modely OpenAI netrénují na nahraných datech a je zajištěna alespoň elementární datová bezpečnost. To kolegům usnadňuje například práci s evropskými síťovými kodexy, pomoc při základních administrativních úkonech, vylepšování inzerátů volných pracovních pozic či jiné běžné činnosti.

Obrázek č. 1: Tři úrovně implementace umělé inteligence v ČEPS
Zdroj: ČEPS, a.s.
Co zahrnují druhá a třetí úroveň?
Druhá úroveň se týká interních dat a komplikovanějších řešení. K tomu využíváme portfolio služeb od Microsoftu – především Copilot, který je u nás autorizovaný pro využití s interními daty. Zásadní je, že ačkoli Copilot využívá jazykový model GPT-5 od OpenAI, činí tak výhradně v kontextu, který mu poskytne uživatel, respektive organizace. Data by v tomto případě neměla opustit Evropskou unii, na což Microsoft poskytuje garanci. Součástí druhé úrovně je také vytváření tzv. agentů v Copilot Studio.
Plánujeme využít nástroj Azure AI Foundry, který umožňuje sestavení komplexního řešení typu Retrieval-Augmented Generation (RAG). To už se dostáváme na hranici třetí úrovně – na níž pracujeme s citlivými interními daty, která nechceme posílat ani Microsoftu. Pro takové účely máme vlastní hardware s vlastním LLM, díky čemuž data neopustí naši společnost.
„Usilujeme o rovnováhu mezi komplexitou a datovou bezpečností.
O jaké účely se jedná?
Systém RAG nad vlastním „železem“ a open-source softwarem používáme například pro tzv. „dispečerovu mámu“. Funguje tak, že se dispečer v podobném uživatelském prostředí, jaké nabízí ChatGPT, ptá na otázku – typicky týkající se směrnic, provozních postupů či jiné interní dokumentace.
V tomto případě je zásadní, aby si model co nejméně vymýšlel. Proto zvyšujeme jeho přesnost pomocí předem vystavěné vektorové databáze, která obsahuje definovanou sadu interních dokumentů. Model navíc díky tzv. primingu ví, že nemá fabulovat, pokud v dokumentaci nenajde vhodnou odpověď. Zvolené nasazené jazykové modely mají architekturu známou jako „mixture of experts“, která snižuje hardwarovou náročnost i čas potřebný k vygenerování odpovědi. Výsledkem je mnohem spolehlivější odpověď než od běžných, veřejně dostupných LLM. Celý proces probíhá výhradně na našem hardwaru a za využití veřejně dostupných open-source řešení: například OpenAI GPT-OSS, Open WebUI nebo Ollama.
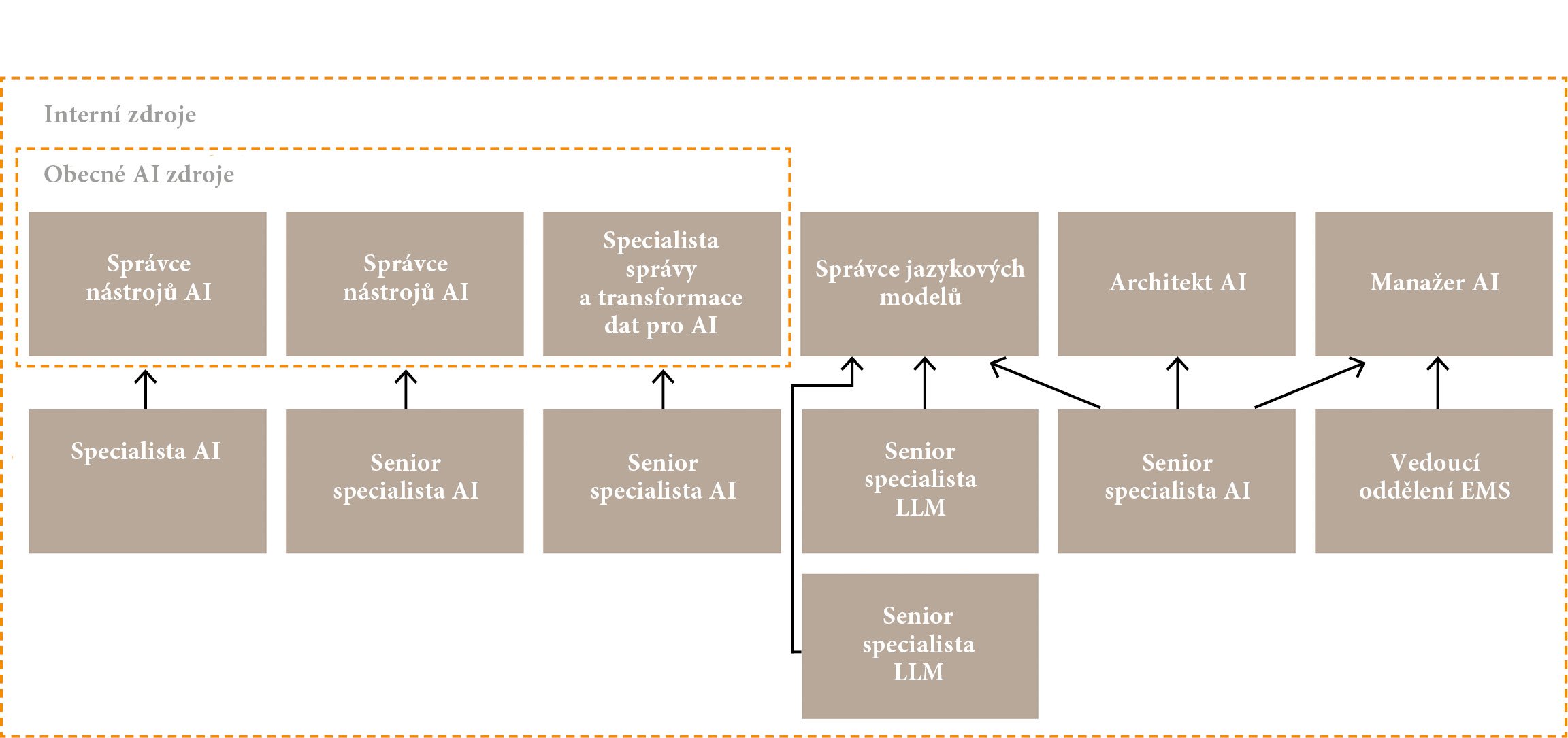
Obrázek č. 2: Cílový stav AI týmu v ČEPS
Zdroj: ČEPS, a.s.
Souvisí využití open-source řešení s potřebou zajistit bezpečnost dat?
Ne přímo, nicméně jsou zdarma a rozumíme jejich fungování. A pokud je nasadíme v uzavřeném prostředí, data nám neutečou. Open-source řešení zmiňuji především proto, že podobný systém si může v dnešní době postavit téměř každý. Jen tomu málokdo rozumí.
Jak se skládá tým, který umělé inteligenci opravdu rozumí? A jak do oddělení zapadá?
Naše oddělení se skládá ze tří týmů: energetického, DevOps a AI. Každý tým má svého lídra, který je expertem v dané doméně. Energetici se starají o dispečerský systém: tvorbu modelu sítě, estimaci stavu, load flow, kontingenční analýzu či zmiňovaný Security Constrained OPF. Tým DevOps se věnuje vývoji a správě vlastních aplikací s hlavním zaměřením na podporu sekcí Energetický trh a Dispečerské řízení. Tým AI má na starost aplikované strojové učení v oblasti energetiky a adopci velkých jazykových modelů.
Složit kvalitní tým pro LLM bylo extrémně náročné, ale povedlo se. Máme například schopné kolegy, kteří absolvovali obor Umělá inteligence na Katedře kybernetiky Západočeské univerzity. Pro rozvoj týmu využívám mimo jiné test CliftonStrengths, který umožňuje strukturovanou diskusi o silných stránkách jednotlivých kolegů a jejich efektivní kariérní růst. Díky tomuto přístupu se u nás absolvent může posunout ze správce aplikací přes softwarového architekta až na doménového lídra.
O DOTAZOVANÉM
 Přemysl Voráč absolvoval obor Kybernetika na Západočeské univerzitě v Plzni, v roce 2018 ve stejném oboru získal doktorský titul. Ve společnosti ČEPS pracuje od roku 2015. Nejprve se v oddělení EMS jako vývojář podílel na implementaci modelu CGMES, od roku 2019 oddělení vede.
Přemysl Voráč absolvoval obor Kybernetika na Západočeské univerzitě v Plzni, v roce 2018 ve stejném oboru získal doktorský titul. Ve společnosti ČEPS pracuje od roku 2015. Nejprve se v oddělení EMS jako vývojář podílel na implementaci modelu CGMES, od roku 2019 oddělení vede.
Související články
Barometr udržitelné výstavby 2026: V Česku se udržitelnost posouvá od uhlíku k energiím a nákladům
Český přístup k udržitelnosti ve stavebnictví zůstává výrazně pragmatický. Debata se stále více posouvá od obecné otázky ,,proč bý…
OTE: Změny v pravidlech pro poskytování agregace, flexibility a akumulace energie
Již za několik dní vstoupí v účinnost významné změny v oblastech agregace flexibility, poskytování flexibility a akumulace energie…
Analýza: Jaké dopady bude mít na solární sektor nový ambiciózní plán elektrifikace EU?
Evropská komise minulý pátek představila veřejnosti Electrification Action Plan. Tento dokument přinášejí konkrétní závazky a nové…
Žiadne peniaze zadarmo. Fabriky dostanú úľavy pri emisiách, len ak investujú do čistejšej výroby
Európsky ťažký priemysel a elektrárne získali roky k dobru. Európska komisia navrhla v reforme trhu s uhlíkom spomaliť tempo znižo…
Teplárenstvo nebude ani tak o objeme, ako správnom načasovaní výroby, vysvetľujú experti
Výroba tepla už dávno nie je len o kotloch a jednom palive. Rastúci podiel obnoviteľných zdrojov, výkyvy cien energií a nové možno…
Kalendář akcí
Fotovoltaika a akumulace v praxi 2026
Konference Energetika 2026
Jesenná konferencia SPNZ 2026
Dny kogenerace 2026
ENERGY-HUB je moderní nezávislá platforma pro průběžné sdílení zpravodajství a analytických článků z energetického sektoru. V rámci našeho portfolia nabízíme monitoring českého, slovenského i zahraničního tisku.


